springboot整合ToolGood.Words进行敏感词过滤
ToolGood.Words是一款高性能非法词(敏感词)检测组件,附带繁体简体互换,支持全角半角互换,获取拼音首字母,获取拼音字母,拼音模糊搜索等功能。 我们可以使用这个项目做一个敏感词过滤系统;为什么要用这个做敏感词过滤,因为效率高速度快啊。直接开始不想废话!
协议:CC BY-SA 4.0 https://creativecommons.org/licenses/by-sa/4.0/
版权声明:本文为原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
一、下载ToolGood.Words源代码导入到STS(eclipse)中
项目的下载地址如下:https://github.com/toolgood/ToolGood.Words/releases/tag/3.0.2.3
有点慢,耐心等一下。
注意看这个项目的README.MD文件
然后导入java这个项目打包,我自己改造了一下生成的sensitive-words-3.0.2.3.jar
这个java项目下自带敏感词库,你也可以不实用他提供的敏感词库,自己建自己的敏感词库。
二、使用方法
2.1项目搭建
使用打包好的jar包,然后再pom.xml中引入
1.创建springboot项目
2.引入依赖
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<lombok.version>1.18.10</lombok.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--kafka依赖-->
<dependency>
<groupId>sensitive</groupId>
<artifactId>sensitive-words</artifactId>
<version>3.0.2.3</version>
</dependency>
<!--lombok依赖-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
</dependency>
</dependencies>
3.配置application.yml整合kafka和redis
server:
port: 8889
2.1.1 过滤方法使用
创建controller包并添加SeckillController类
package com.example.demo.controller;
import java.util.ArrayList;
import java.util.List;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.bind.annotation.RestController;
import toolgood.words.StringSearch;
import toolgood.words.WordsHelper;
@RestController
@RequestMapping("/test")
public class SensitiveWordController {
@GetMapping("/sensitive")
@ResponseBody
public Object sensitiveWord() throws Exception {
/**
* 1.第一步初始化敏感词汇数据为一个list集合(可以通过配置文件获取,也可以是数据,甚至可以做成单例模式获取)我们以简单的配置到配置文件中
* 2.可以直接通过配置文件获取,如果可以做到实时添加敏感词汇,可以使用数据库的形势存储(或者文本存储,阿里的Nacos)。
*/
List<String> list = new ArrayList<String>();
list.add("中国");
StringSearch iwords = new StringSearch();
iwords.SetKeywords(list);
/**
* 3.需要过滤的字符串为formatStr,需要转为简体
*/
String formatStr = WordsHelper.ToSimplifiedChinese("我愛中國");
//查询出所有的匹配字段
//List<String> all = iwords.FindAll(formatStr);
//替换查询出的匹配字段
return iwords.Replace(formatStr, '*');
}
}
返回的json为
我爱**
但是这有一个问题,我测试后发现他不能正反识别
比如”江阴毛纺厂” 这个词,如果你设置了敏感词汇,会直接替换为”江**纺厂”这个有待加强
至于这个问题如何解决
alex-sensitive-words-filter-3.0.jar这个包
下载地址:链接: https://pan.baidu.com/s/1d333YbJb9oLykLDM64kbYw 提取码: kmfs
想要下载这个包可以直接去百度云盘csdn上太贵了。我研究了一下不好用。
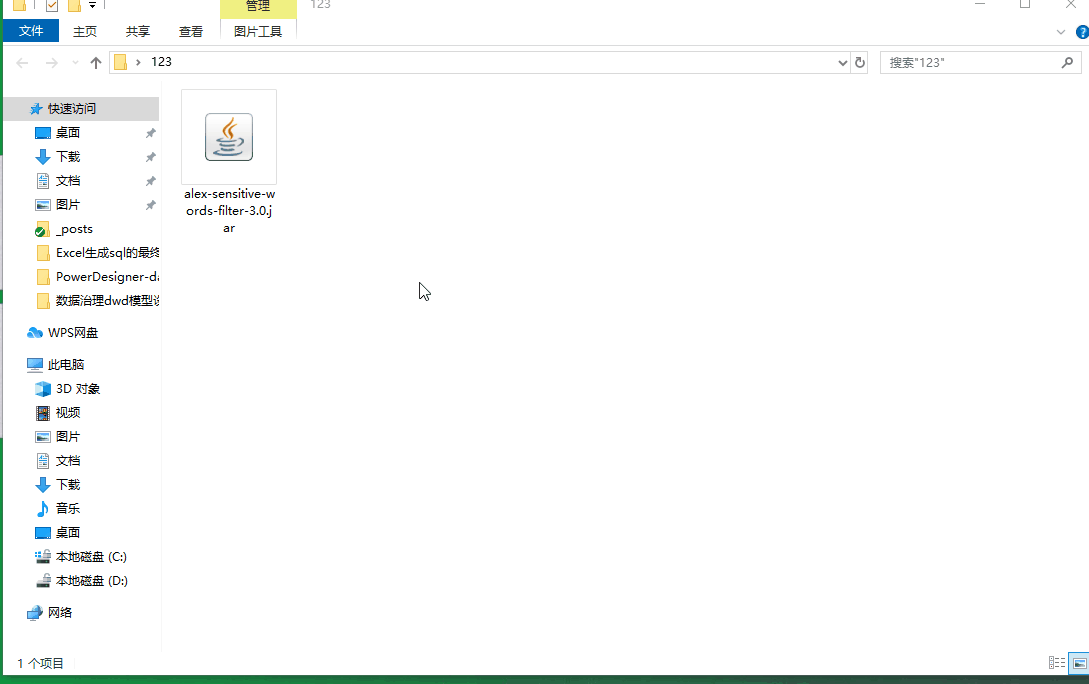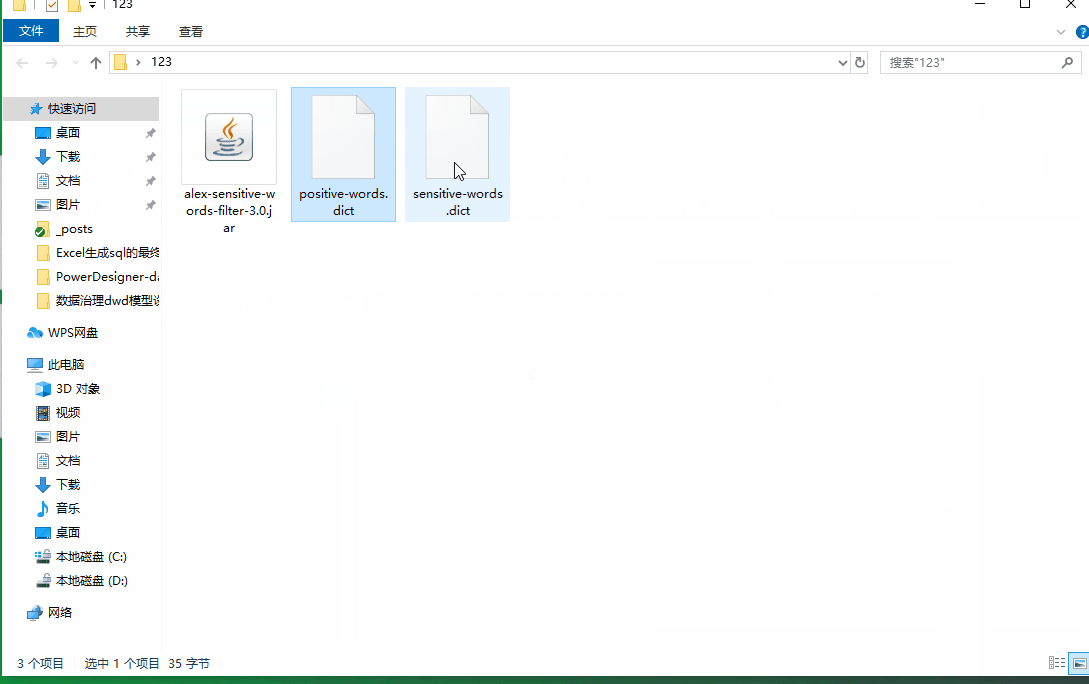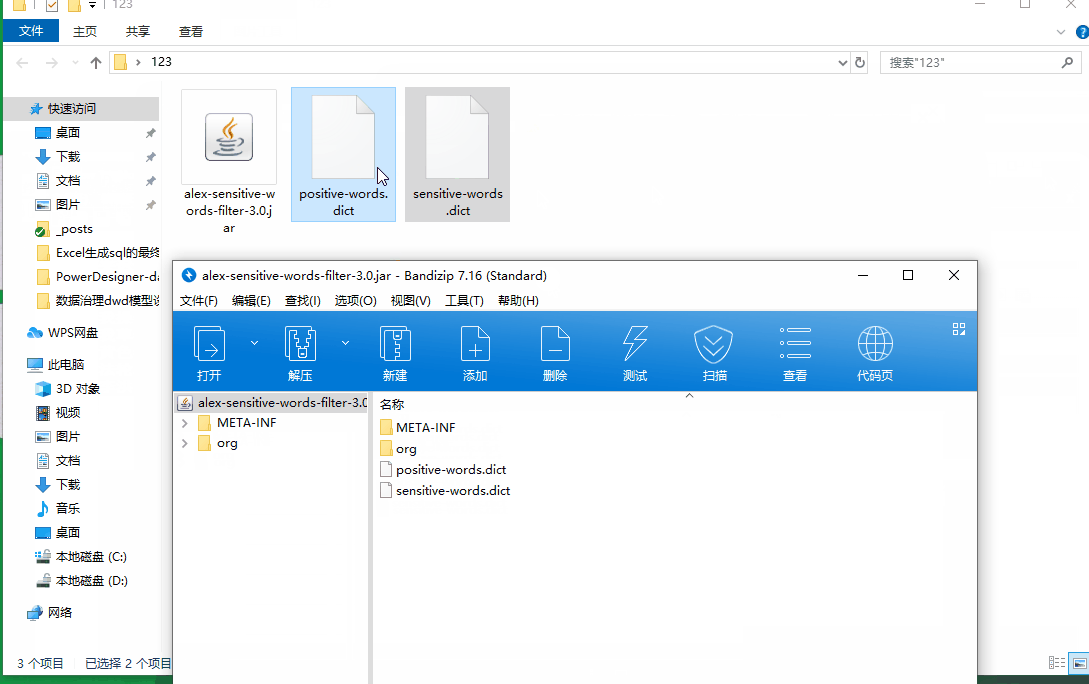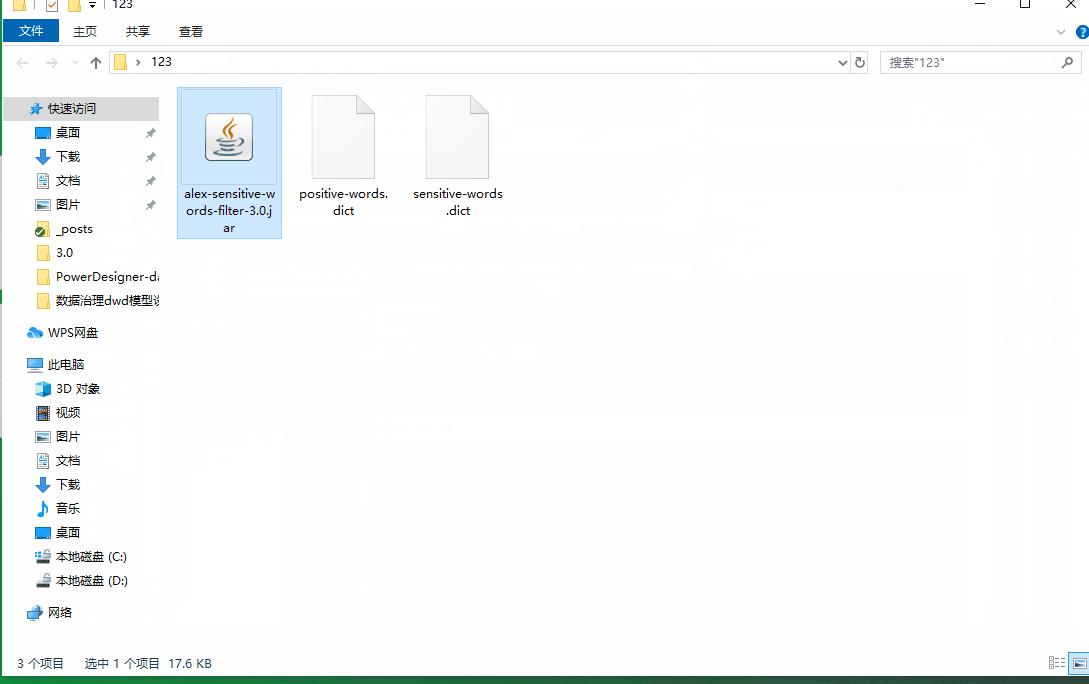
缺点:需要手动修改jar里的字典内容,如果临时要加敏感字就需要换包
优点:可以设置哪些字不需要过滤
我测试返回的方法如下:
package com.example.demo.controller;
import java.util.ArrayList;
import java.util.List;
import org.alex.words.filter.WordsFilterUtil;
import org.alex.words.filter.result.FilteredResult;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("/test")
public class SensitiveWordController {
@GetMapping("/sensitive")
@ResponseBody
public Object sensitiveWordNew() throws Exception {
FilteredResult strFilter = WordsFilterUtil.simpleFilter("网站黄色漫画网站", '*');
FilteredResult strFilter1 = WordsFilterUtil.filterTextWithPunctation("网【站■黄●色★漫▲画■网■站", '*');
FilteredResult strFilter2 = WordsFilterUtil.filterHtml("<html>网站<font>黄</font>.<色<script>,漫,画,网站</html>", '*');
List<String> list = new ArrayList<>();
list.add("1->FilteredContent>>> "+strFilter.getFilteredContent());
list.add("1->BadWords>>> "+strFilter.getBadWords());
list.add("1->GoodWords>>> "+strFilter.getGoodWords());
list.add("1->OriginalContent>>> "+strFilter.getOriginalContent());
list.add("1->HasSensiviWords>>> "+strFilter.getHasSensiviWords());
list.add("1->Level>>> "+strFilter.getLevel());
list.add("2->FilteredContent>>> "+strFilter1.getFilteredContent());
list.add("2->BadWords>>> "+strFilter1.getBadWords());
list.add("2->GoodWords>>> "+strFilter1.getGoodWords());
list.add("2->OriginalContent>>> "+strFilter1.getOriginalContent());
list.add("2->HasSensiviWords>>> "+strFilter1.getHasSensiviWords());
list.add("2->Level>>> "+strFilter1.getLevel());
list.add("3->FilteredContent>>> "+strFilter2.getFilteredContent());
list.add("3->BadWords>>> "+strFilter2.getBadWords());
list.add("3->GoodWords>>> "+strFilter2.getGoodWords());
list.add("3->OriginalContent>>> "+strFilter2.getOriginalContent());
list.add("3->HasSensiviWords>>> "+strFilter2.getHasSensiviWords());
list.add("3->Level>>> "+strFilter1.getLevel());
FilteredResult strFilter3 = WordsFilterUtil.filterTextWithPunctation("江阴毛纺厂和大江阴毛厂生产的毛巾珊珊来迟", '*');
list.add("4->FilteredContent>>> "+strFilter3.getFilteredContent());
list.add("4->BadWords>>> "+strFilter3.getBadWords());
list.add("4->GoodWords>>> "+strFilter3.getGoodWords());
list.add("4->OriginalContent>>> "+strFilter3.getOriginalContent());
list.add("4->HasSensiviWords>>> "+strFilter3.getHasSensiviWords());
list.add("4->Level>>> "+strFilter3.getLevel());
FilteredResult result1 = WordsFilterUtil.filterTextWithPunctation("网■站■黄■色■漫▲画■网■站", '*');
list.add("5->FilteredContent>>> "+result1.getFilteredContent());
list.add("5->BadWords>>> "+result1.getBadWords());
list.add("5->GoodWords>>> "+result1.getGoodWords());
list.add("5->OriginalContent>>> "+result1.getOriginalContent());
list.add("5->HasSensiviWords>>> "+result1.getHasSensiviWords());
list.add("5->Level>>> "+result1.getLevel());
return list;
}
}
返回的结果
[
"1->FilteredContent>>> 网站**漫画网站",
"1->BadWords>>> 黄色,",
"1->GoodWords>>> ",
"1->OriginalContent>>> 网站黄色漫画网站",
"1->HasSensiviWords>>> true",
"1->Level>>> 1.0",
"2->FilteredContent>>> 网【站■*●*★漫▲画■网■站",
"2->BadWords>>> 黄色,",
"2->GoodWords>>> ",
"2->OriginalContent>>> 网【站■黄●色★漫▲画■网■站",
"2->HasSensiviWords>>> true",
"2->Level>>> 1.0",
"3->FilteredContent>>> <html>网站<font>*</font>.<*<script>,漫,画,网站</html>",
"3->BadWords>>> 黄色,",
"3->GoodWords>>> ",
"3->OriginalContent>>> <html>网站<font>黄</font>.<色<script>,漫,画,网站</html>",
"3->HasSensiviWords>>> true",
"3->Level>>> 1.0",
"4->FilteredContent>>> 江阴毛纺厂和大江阴毛厂生产的毛巾珊珊来迟",
"4->BadWords>>> ",
"4->GoodWords>>> 江阴毛纺,",
"4->OriginalContent>>> 江阴毛纺厂和大江阴毛厂生产的毛巾珊珊来迟",
"4->HasSensiviWords>>> false",
"4->Level>>> 0.0",
"5->FilteredContent>>> 网■站■*■*■漫▲画■网■站",
"5->BadWords>>> 黄色,",
"5->GoodWords>>> ",
"5->OriginalContent>>> 网■站■黄■色■漫▲画■网■站",
"5->HasSensiviWords>>> true",
"5->Level>>> 1.0",
]
FilteredContent:意思是过滤后的内容
BadWords:是字典中的是否有需要过滤的这个字符串
GoodWords:这个是白名单不过滤此字符串
HasSensiviWords:是否还有敏感字符串
Level:在字典里设置的等级
jar包里的文件 sensitive-words.dict是黑名单的意思,需要过滤的写在里面
jar包里的文件 positive-words.dict是白名单的意思,不需要过滤的写在里面
手动修改字典的方法请看下图
=====================================================================
微信公众号:
![]()