MySQL 查询重复数据,删除重复数据保留id最小的一条作为唯一数据
最近在做一个批量数据导入到MySQL数据库的功能,从批量导入就可以知道,这样的数据在插入数据库之前是不会进行重复判断的,因此只有在全部数据导入进去以后在执行一条语句进行删除,保证数据唯一性。
安装环境
系统:CentOS7.4
java jdk 1.8
MySQL版本:5.7
一.表结构如下图所示:
表的名称是:brand
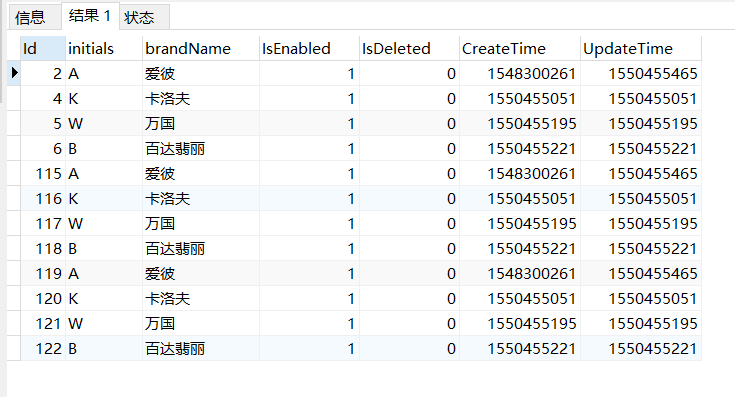
二.使用SQL语句查询重复的数据有哪些:
SELECT * from brand WHERE brandName IN(
select brandName from brand GROUP BY brandName HAVING COUNT(brandName)>1 #条件是数量大于1的重复数据
)
更加简单快捷的方式:
这是老飞飞的前辈给了一个更加方便,简洁的写法(非常感谢大佬的方法):
DELETE FROM brand WHERE Id NOT IN (SELECT Id FROM (SELECT MIN(Id) AS Id FROM brand GROUP BY brandName) t)
这句的意思其实就是,通过分组统计出数据库中不重复的最小数据id编号,让后通过 not in 去删除其他重复多余的数据。
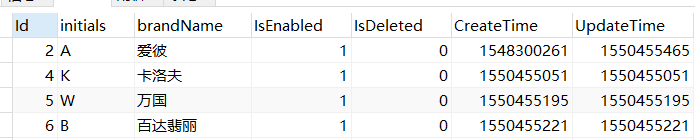
结果如下图:
=======================================================================================
博客地址:https://www.codepeople.cn
=======================================================================================
微信公众号:
![]()